System
Enabling Over-the-Air AI for Edge Computing via Metasurface-Driven Physical Neural Networks
Chao Feng, Shuo Liang, Gaogeng Zhao, Beier Jing, Yaxiong Xie, Xiaojiang Chen
Sigcomm’25 (CCF-A) 2025
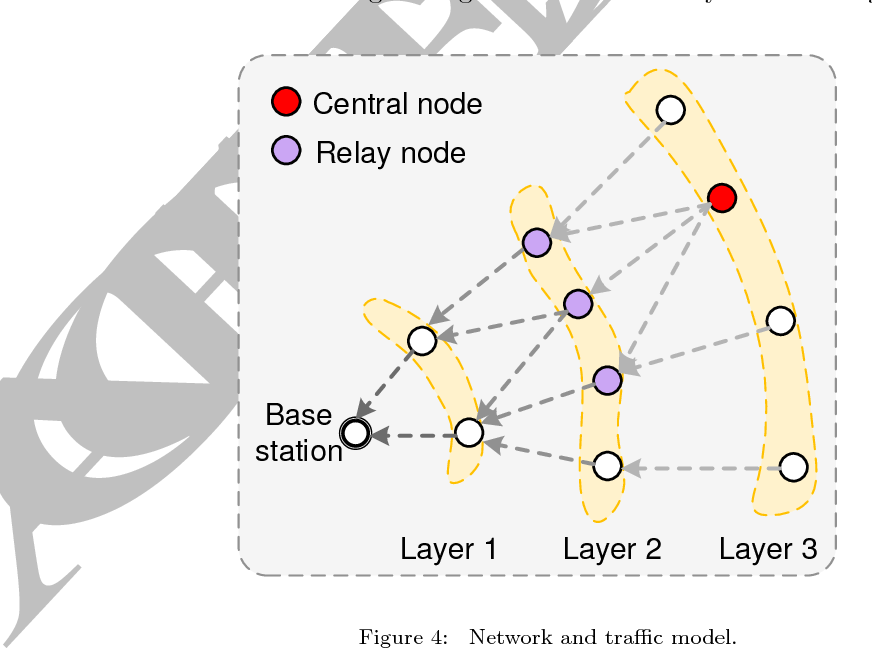
We present MetaAI, a novel wireless computing paradigm that integrates neural network computation directly into wireless signal propagation. Unlike traditional approaches that treat wireless channels as mere data conduits, MetaAI transforms them into active computing elements through programmable metasurfaces, enabling concurrent data transmission and neural network processing. By leveraging the inherent linearity of both wireless propagation and neural networks, our design resolves the fundamental mismatch between sequential wireless transmission and parallel neural computation, while supporting efficient multi-sensor late-stage data fusion. We implemented MetaAI using metasurfaces at both dualband (2.4/5 GHz) and single-band (3.5 GHz) frequencies. Extensive experiments demonstrate robust performance across diverse classification tasks, achieving 82.8% average accuracy (up to 89.8%) even with a simple linear architecture. Multi-sensor fusion further improves accuracy by up to 27.06%. MetaAI represents a fundamental shift in Edge AI architecture, where wireless infrastructure becomes an integral part of the computing pipeline.
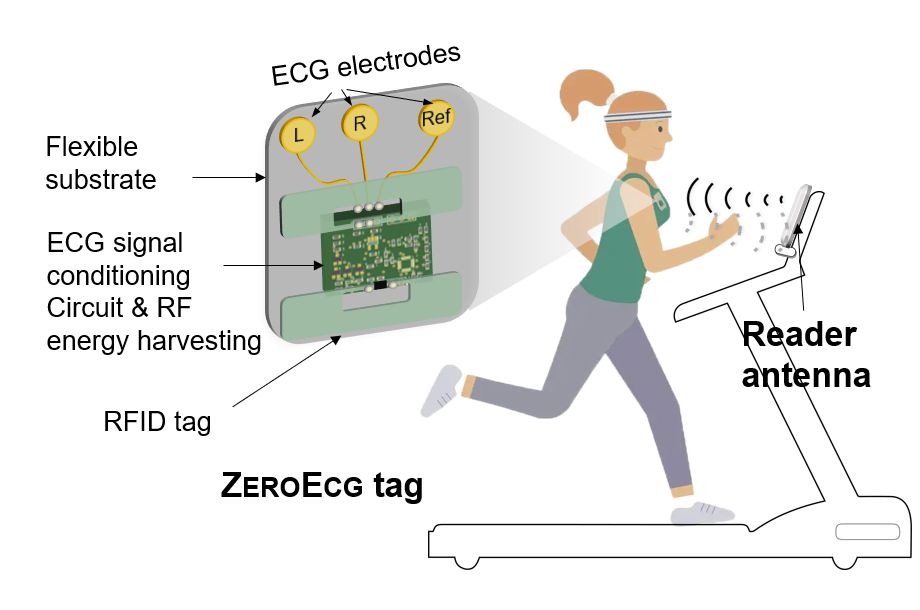
ZEROECG: Zero-Sensation ECG Monitoring By Exploring RFID MOSFET
Wenli Jiao, Ju Wang, Xinzhuo Gao, Long Du, Yanlin Li, Lili Zhao, Dingyi Fang, Xiaojiang Chen
Mobicom’24 (CCF-A)
ECG monitoring during human activities is crucial since many heart attacks occur when people are exercising, driving a car, operating a machine, etc. Unfortunately, existing ECG monitoring devices fail to timely detect abnormal ECG signals during activities due to the need for many cables or a sustained press on devices (e.g., smartwatches). This paper introduces ZEROECG, a wireless, battery-free, lightweight, electronic-skin-like tag integrated with commodity RFIDs, which can continuously track a user’s ECG during activities. By exploring and leveraging the RFID MOSFET switch, which is traditionally used for backscatter modulation, we map the ECG signal to the RFID RSS and phase measurement. It opens a new RFID sensing approach for sensing any physical world variable that can be translated into voltage signals. We model and analyze the RFID MOSFET-based backscatter modulation principle, providing design guidance for other sensing tasks. Real-world results illustrate the effectiveness of ZEROECG on ECG sensing.
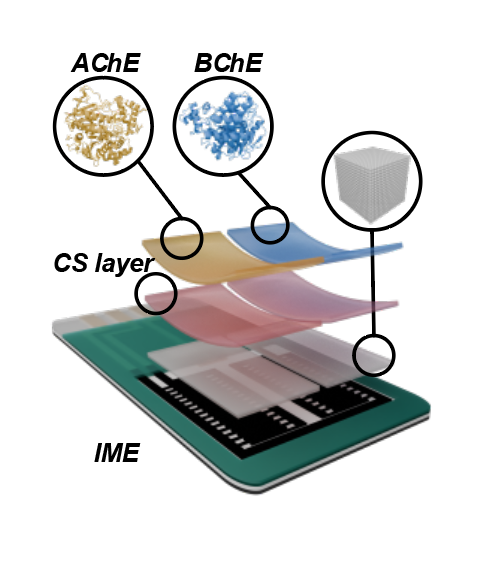
Hornbill: A Portable, Touchless, and Battery-Free Electrochemical Bio-tag for Multi-pesticide Detection
Guorong He, Yaxiong Xie, Chao Zheng, Longlong Zhang, Qi Wu1, Wenyan Zhang, Dan Xu, Xiaojiang Chen
Mobicom’24 (CCF-A)
Pesticide overuse poses significant risks to human healthand environmental integrity. Addressing the limitations ofexisting approaches, which struggle with the diversity ofpesticide compounds, portability issues, and environmentalsensitivity, this paper introduces Hornbill. A wireless andbattery-free electrochemical bio-tag that integrates the advantages of NFC technology with electrochemical biosensorsfor portable, precise, and touchless multi-pesticide detection.The basic idea of Hornbill is comparing the distinct electrochemical responses between a pair of biological receptorsand different pesticides to construct a unique set of featurefingerprints to make multi-pesticide sensing feasible. To incorporate this idea within small NFC tags, we reengineer theelectrochemical sensor, spanning the antenna to the voltageregulator. Additionally, to improve the system’s sensitivityand environmental robustness, we carefully design the electrodes by combining microelectrode technology and materials science. Experiments with 9 different pesticides show thatHornbill achieves a mean accuracy of 93% in different concentration environments and its sensitivity and robustnesssurpass that of commercial electrochemical sensors.

Gastag: A Gas Sensing Paradigm using Graphene-based Tags
Xue Sun, Jie Xiong, Chao Feng, Xiaohui Li, Jiayi Zhang, Binghao Li, Dingyi Fang, Xiaojiang Chen
Mobicom’24 (CCF-A)
Gas sensing plays a key role in detecting explosive/toxic gases and monitoring environmental pollution. Existing approaches usually require expensive hardware or high maintenance cost, and are thus ill-suited for large-scale long-term deployment. In this paper, we propose Gastag, a gas sensing paradigm based on passive tags. The heart of Gastag design is embedding a small piece of gas-sensitive material to a cheap RFID tag. When gas concentration varies, the conductivity of gas-sensitive materials changes, impacting the impedance of the tag and accordingly the received signal. To increase the sensing sensitivity and gas concentration range capable of sensing, we carefully select multiple materials and synthesize a new material that exhibits high sensitivity and high surface-to-weight ratio. To enable a long working range, we redesigned the tag antenna and carefully determined the location to place the gas-sensitive material in order to achieve impedance matching. Comprehensive experiments demonstrate the effectiveness of the proposed system. Gastag can achieve a median error of 6.7 ppm for CH4 concentration measurements, 12.6 ppm for CO2 concentration measurements, and 3 ppm for CO concentration measurements, outperforming a lot of commodity gas sensors on the market. The working range is successfully increased to 8.5 m, enabling the coverage of many tags with a single reader, laying the foundation for large-scale deployment.

Cyclops: A Nanomaterial-based, Baterry-Free Intraocular Pressure (IOP) Monitoring System inside Contact Lens
Liyao Li, Bozhao Shang, Yun Wu, Jie Xiong, Xiaojiang Chen, Yaxiong Xie
NSDI’24 (CCF-A) 2024
Intraocular pressure (IOP), commonly known as eye pressure, is a critical physiological parameter related to health. Contact lens-based IOP sensing has garnered significant attention in research. Existing research has been focusing on developing the sensor itself, so the techniques used to read sensing data only support a reading range of several centimeters, becoming the main obstacle for real-world deployment. This paper presents Cyclops, the first battery-free IOP sensing system integrated into a contact lens, which overcomes the proximity constraints of traditional reading methods. Cyclops features a three-layer antenna comprising two metallic layers and a nanomaterial-based sensing layer in between. This innovative antenna serves a dual purpose, functioning as both a pressure sensor and a communication antenna simultaneously. The antenna is connected to an RFID chip, which utilizes a low-power self-tuning circuit to achieve high-precision pressure sensing, akin to a 9-bit ADC. Extensive experimental results demonstrate that Cyclops supports communication at meter-level distances, and its IOP measurement accuracy surpasses that of commercial portable IOP measurement devices.
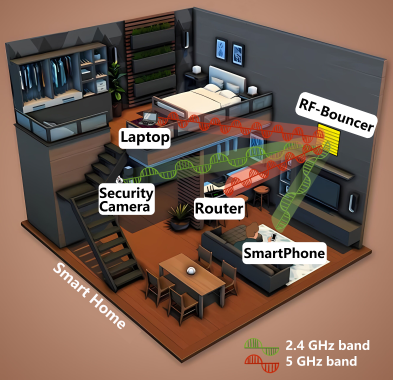
RF-Bouncer: A Programmable Dual-band Metasurface for Sub-6 Wireless Networks
Xinyi Li, Chao Feng, Xiaojing Wang, Yangfan Zhang, Yaxiong Xie, Xiaojiang Chen
NSDI '23 (CCF-A) 2023
Offloading the beamforming task from the endpoints to the metasurface installed in the propagation environment has attracted significant attention. Currently, most of the metasurface-based beamforming solutions are designed and optimized for operation on a single ISM band (either 2.4 GHz or 5 GHz). In this paper, we propose RF-Bouncer, a compact, low-cost, simple-structure programmable dual-band metasurface that supports concurrent beamforming on two Sub-6 ISM bands. By configuring the states of the meta-atoms, the metasurface is able to simultaneously steer the incident signals from two bands towards their desired departure angles. We fabricate the metasurface and validate its performance via extensive experiments. Experimental results demonstrate that RF-Bouncer achieves 15.4 dB average signal strength improvement and a 2.49× throughput improvement even with a relatively small 16 × 16 array of meta-atoms.
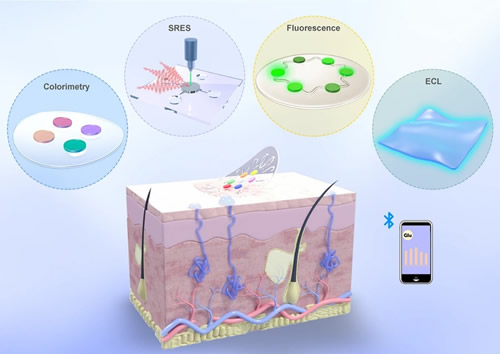
BioScatter: Low Power Sweat Sensing with Backscatter
Wenli Jiao, Yanlin Li, Xiangdong Xi, Ju Wang, Dingyi Fang, Xiaojiang Chen
MobiSys'23 (CCF-B)
This paper introduces BioScatter, a backscatter-based accurate and ultra-low-power sweat-sensing wearable sensor that does not need any energy-hungry ADC, DAC, and active radios. The key to eliminating DAC is a novel low-power voltage sweeping circuit design that can perform as well as a 12-bit DAC. To eliminate the ADC, we borrow backscatter technology that can directly transmit the measured analog sensing values to the reader, thus avoiding digital sampling. Extensive results show that BioScatter has a low-power consumption of 313.5 μW and achieves more than 98.5% sensing accuracy for detecting five concentration levels of three types of important bio-fluid in sweat.
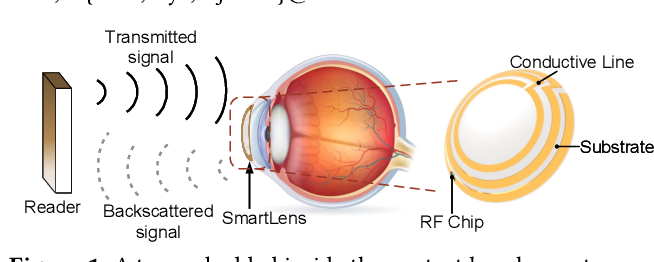
SmartLens: Sensing Eye Activities Using Zero-power Contact Lens
Liyao Li, Yaxiong Xie, Jie Xiong, Ziyu Hou, Yingchun Zhang, Qing We, Fuwei Wang, Dingyi Fang, Xiaojiang Chen
MobiCom’22 (CCF-A) 2022
As the most important organs of sense, human eyes perceive 80% information from our surroundings. Eyeball movement is closely related to our brain health condition. Eyeball movement and eye blink are also widely used as an efficient human-computer interaction scheme for paralyzed individuals to communicate with others. Traditional methods mainly use intrusive EOG sensors or cameras to capture eye activity information. In this work, we propose a system named SmartLens to achieve eye activity sensing using zero-power contact lens. To make it happen, we develop dedicated antenna design which can be fitted in an extremely small space and still work efficiently to reach a working distance more than 1 m. To accurately track eye movements in the presence of strong self-interference, we employ another tag to track the user's head movement and cancel it out to support sensing a walking or moving user. Comprehensive experiments demonstrate the effectiveness of the proposed system. At a distance of 1.4 m, the proposed system can achieve an average accuracy of detecting the basic eye movement and blink at 89.63% and 82%, respectively.
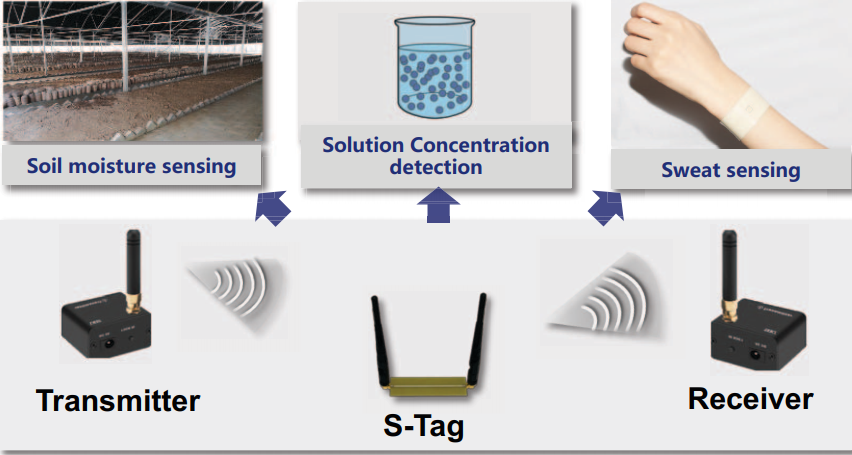
Eliminating Design Effort: A Reconfigurable Sensing Framework For Chipless, Backscatter Tags
Wenli Jiao, Ju Wang, Yelu He, Xiangdong Xi, Fuwei Wang, Dingyi Fang, Xiaojiang Chen
2022 21st ACM/IEEE International Conference on Information Processing in Sensor Networks (IPSN) 2022
Backscatter tag based sensing has received a lot of attention recently due to the battery-free, low-cost and widespread use of backscatter tags, e.g., RFIDs. Despite that, they suffer from an ex-tensive, costly, and time-consuming redesign effort when there are changes in application requirements, such as changes in sensing targets or working frequency bands. This paper introduces a reconfigurable sensing framework, which enables us to easily reconfigure the design parameters of chipless backscatter tags for sensing different targets or working with differ-ent frequency bands, without the need of onerous design effort. To realize this vision, we capture the relationship between the application requirements and the sensing tag's design parameters. This relationship enables us to fast and efficiently reconfigure/change an existing sensing tag design for meeting new application requirements. Real-world experiments show that, by using our reconfig-urable framework to flexibly redesign a tag's parameters, the sensing tag achieves more than 92.1 % accuracy for sensing four different applications and working on four different frequency bands.
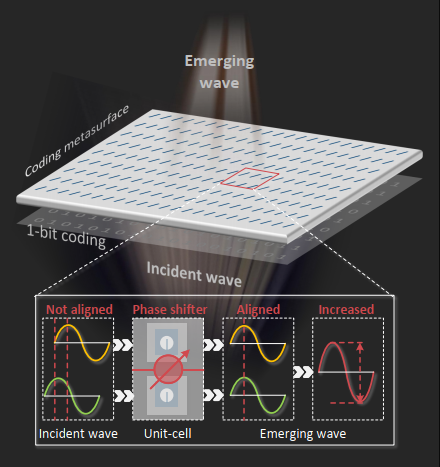
RFlens: Metasurface-Enabled Beamforming for IoT Communication and Sensing
Chao Feng, Xinyi Li, Yangfan Zhang, XiaoJing Wang, LiQiong Chang, FuWei Wang, Xinyu Zhang, Xiaojiang Chen
MobiCom’21 (CCF-A) 2021
Beamforming can improve the communication and sensing capabilities for a wide range of IoT applications. However, most existing IoT devices cannot perform beamforming due to form factor, energy, and cost constraints. This paper presents RFlens, a reconfigurable metasurface that empowers low-profile IoT devices with beamforming capabilities. The metasurface consists of many unit-cells, each acting as a phase shifter for signals going through it. By encoding the phase shifting values, RFlens can manipulate electromagnetic waves to "reshape" and resteer the beam pattern. We prototype RFlens for 5 GHz Wi-Fi signals. Extensive experiments demonstrate that RFlens can achieve a 4.6 dB median signal strength improvement (up to 9.3 dB) even with a relatively small 16 × 16 array of unit-cells. In addition, RFlens can effectively improve the secrecy capacity of IoT links and enable passive NLoS wireless sensing applications.
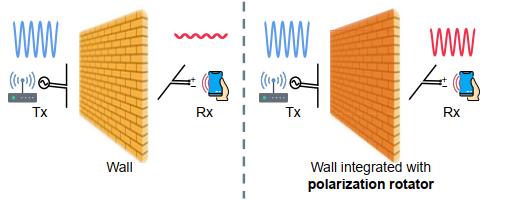
Pushing the Physical Limits of IoT Devices with Programmable Metasurface
Lili Chen, Wenjun Hu, Kyle Jamieson, Xiaojiang Chen, Dingyi Fang, Jeremy Gummeson
NSDI’21 (CCF-A) 2021
Small, low-cost IoT devices are typically equipped with only a single, low-quality antenna, significantly limiting communication range and link quality. In particular, these antennas are typically linearly polarized and therefore susceptible to polarization mismatch, which can easily cause 10-15 dBm of link loss on communication to and from such devices. In this work, we highlight this under-appreciated issue and propose the augmentation of IoT deployment environments with programmable, RF-sensitive surfaces made of metamaterials. Our smart metasurface mitigates polarization mismatch by rotating the polarization of signals that pass through or reflects off the surface. We integrate our metasurface into an IoT network as LLAMA, a Low-power Lattice of Actuated Metasurface Antennas, designed for the pervasively used 2.4 GHz ISM band. We optimize LLAMA's metasurface design for both low transmission loss and low cost, to facilitate deployment at scale. We then build an end-to-end system that actuates the metasurface structure to optimize for link performance in real-time. Our experimental prototype-based evaluation demonstrates gains in link power of up to 15 dB, and wireless capacity improvements of 100 and 180 Kbit/s/Hz in through-surface and surface-reflective scenarios, respectively, attributable to the polarization rotation properties of LLAMA's metasurface.
Algorithm
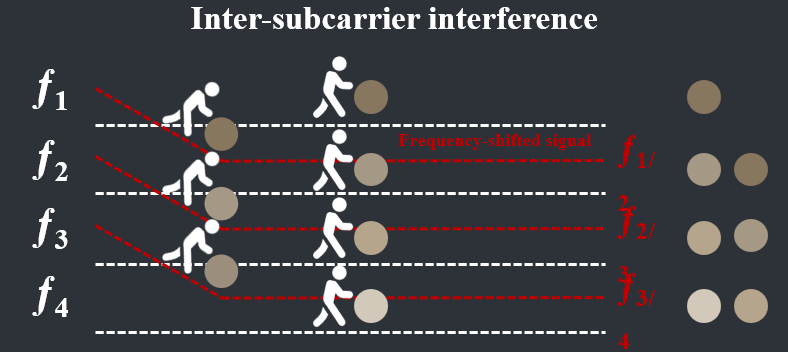
Hydra: Attacking OFDM-base Communication System via Metasurfaces Generated Frequency Harmonics
Yangfan Zhang, Yaxiong Xie, Zhihao Hui, Hao Jia, Xiaojiang Chen
Mobicom’24 (CCF-A)
While Reconfigurable Intelligent Surfaces (RIS) have been shown to enhance OFDM communication performance, this paper unveils a potential security concern arising from widespread RIS deployment. Malicious actors could exploit vulnerabilities to hijack or deploy rogue RIS, transforming them from communication boosters into attackers. We present a novel attack that disrupts the critical orthogonality property of OFDM subcarriers, severely degrading communication performance. This attack is achieved by manipulating the RIS to generate frequency-shifted reflections/harmonics of the original OFDM signal. We also propose algorithms to simultaneously beamform the multiple RIS-generated frequency shifted reflections towards selected targets. Extensive experiments conducted in indoor, outdoor, 3D, and office settings demonstrate that Hydra can achieve a 90% throughput reduction in targeted attack scenarios and a 43% throughput reduction in indiscriminate attack scenarios. Furthermore, we validated the effectiveness of our attacks on both the 802.11 protocol and the 5G NR protocol.

Pushing the Throughput Limit of OFDM-based Wi-Fi Backscatter Communication
Qihui Qin, Kai Chen, Yaxiong Xie, Heng Luo, Dingyi Fang, Xiaojiang Chen
Mobicom’24 (CCF-A)
The majority of existing Wi-Fi backscatter systems transmit tag data at rates lower than 250 kbps, as the tag data is modulated at OFDM symbol level, allowing for demodulation using commercial Wi-Fi receivers. However, it is necessary to modulate tag data at OFDM sample level to satisfy the requirements for higher throughput. A comprehensive theoretical analysis and experimental investigation conducted in this paper demonstrates that demodulating sample-level modulated tag data using commercial Wi-Fi receivers is unattainable due to excessive computational overhead and demodulation errors. This is because the significant tag information dispersion, loss, and shuffling are caused by Wi-Fi physical layer operations. We conclude that the optimal position for demodulation is the time-domain IQ samples, which do not undergo any Wi-Fi physical layer operations and preserve the intact, ordered, and undispersed information of tag-modulated data, thereby minimizing complexity and maximizing accuracy. We devise a demodulation algorithm using time domain IQ samples and implement on two types of demodulator: a dual radio chain demodulator and a single radio chain demodulator. Experiments show that our demodulation algorithm not only decrease the BER by at least three orders of magnitude, but also reduces the time complexity from exponential to linear. It achieves a tag data rate of up to 10 Mbps with QPSK modulation and a BER at 10−4 for the dual radio chain demodulator, and a tag data rate of up to 1 Mbps with BPSK and a BER at 10−4 for the single radio demodulator. We believe our results pave the way for designing Wi-Fi backscatter system with extremely high throughput.
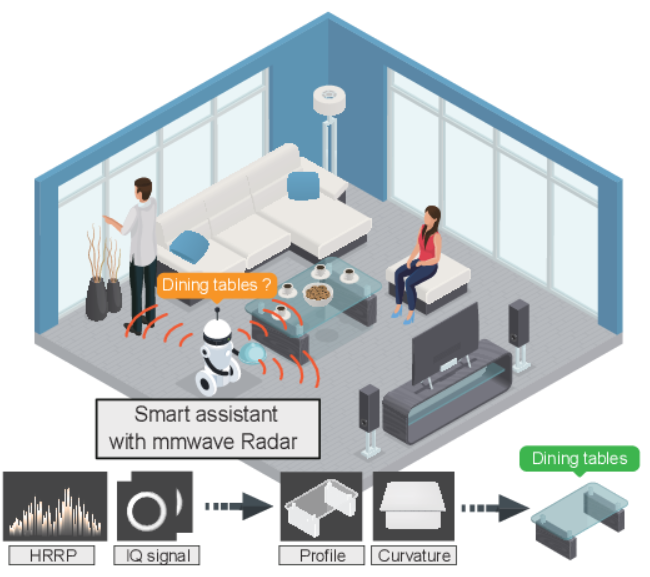
Fusang: Graph-inspired Robust and Accurate Object Recognition on Commodity mmWave Devices
Guorong He, Shaojie Chen, Dan Xu, Xiaojiang Chen, Yaxiong Xie, Xinhuai Wang, Dingyi Fang
MobiSys '23 (CCF-B) 2023
This paper presents the design and implementation of Fusang, a low-barrier system that brings accurate and robust 3D object recognition to Commercial-Off-The-Shelf mmWave devices. The basic idea of Fusang is leveraging the large bandwidth of mmWave Radars to capture a unique set of fine-grained reflected responses generated by object shapes. Moreover, Fusang constructs two novel graph-structured features to robustly represent the reflected responses of the signal in the frequency domain and IQ domain, and carefully designs a neural network to accurately recognize objects even in different multipath scenarios. We have implemented a prototype of Fusang on a commodity mmWave Radar device. Our experiments with 24 different objects show that Fusang achieves a mean accuracy of 97% in different multipath environments.
RF-CM: Cross-Modal Framework for RF-enabled Few-Shot Human Activity Recognition
Xuan Wang, Tong Liu, Chao Feng, Dingyi Fang, Xiaojiang Chen
UbiComp’23 (CCF-A)
Radio-Frequency (RF) based human activity recognition (HAR) enables many attractive applications such as smart home, health monitoring, and virtual reality (VR). Among multiple RF sensors, mmWave radar is emerging as a new trend due to its fine-grained sensing capability. However, laborious data collection and labeling processes are required when employing a radar-based sensing system in a new environment. To this end, we propose RF-CM, a general cross-modal human activity recognition framework. The key enabler is to leverage the knowledge learned from a massive WiFi dataset to build a radar-based HAR system with limited radar samples. It can significantly reduce the overhead of training data collection. In addition, RF-CM can work well regardless of the deployment setups of WiFi and mmWave radar, such as performing environments, users' characteristics, and device deployment. RF-CM achieves this by first capturing the activity-related variation patterns through data processing schemes. It then employs a convolution neural network-based feature extraction module to extract the high-dimensional features to be fed into the activity recognition module. Finally, RF-CM takes the generalization knowledge from WiFi networks as guide labels to supervise the training of the radar model, thus enabling a few-shot radar-based HAR system. We evaluate RF-CM by applying it to two HAR applications, fine-grained American sign language recognition (WiFi-cross-radar) and coarse-grained gesture recognition (WiFi-cross-RFID). The accuracy improvement of over 10% in both applications demonstrates the effectiveness of RF-CM. This cross-modal ability allows RF-CM to support more cross-modal applications.

Akte-Liquid: Acoustic-Based Liquid Identification with Smartphones
Xue Sun, Wenwen Deng, Xudong Wei, Dingyi Fang, Baochun Li, Xiaojiang Chen
ACM Transactions on Sensor Networks (CCF-B) 2023
Liquid identification plays an essential role in our daily lives. However, existing RF sensing approaches still require dedicated hardware such as RFID readers and UWB transceivers, which are not readily available to most users. In this article, we propose Akte-Liquid, which leverages the speaker on smartphones to transmit acoustic signals, and the microphone on smartphones to receive reflected signals to identify liquid types and analyze the liquid concentration. Our work arises from the acoustic intrinsic impedance property of liquids, in that different liquids have different intrinsic impedance, causing reflected acoustic signals of liquids to differ. Then, we discover that the amplitude-frequency feature of reflected signals may be utilized to represent the liquid feature. With this insight, we propose new mechanisms to eliminate the interference caused by hardware and multi-path propagation effects to extract the liquid features. In addition, we design a new Siamese network-based structure with a specific training sample selection mechanism to reconstruct the extracted feature to container-irrelevant features. Our experimental evaluations demonstrate that Akte-Liquid is able to distinguish 20 types of liquids at a higher accuracy, and to identify food additives and measure protein concentration in the artificial urine with a 92.3% accuracy under 1 mg/100 mL as well.
Wi-Learner: Towards One-shot Learning for Cross-Domain Wi-Fi based Gesture Recognition
Chao Feng, Nan Wang, Yicheng Jiang, Xia Zheng, Kang Li, Zheng Wang, Xiaojiang Chen
UbiComp’22 (CCF-A) 2022
Contactless RF-based sensing techniques are emerging as a viable means for building gesture recognition systems. While promising, existing RF-based gesture solutions have poor generalization ability when targeting new users, environments or device deployment. They also often require multiple pairs of transceivers and a large number of training samples for each target domain. These limitations either lead to poor cross-domain performance or incur a huge labor cost, hindering their practical adoption. This paper introduces Wi-Learner, a novel RF-based sensing solution that relies on just one pair of transceivers but can deliver accurate cross-domain gesture recognition using just one data sample per gesture for a target user, environment or device setup. Wi-Learner achieves this by first capturing the gesture-induced Doppler frequency shift (DFS) from noisy measurements using carefully designed signal processing schemes. It then employs a convolution neural network-based autoencoder to extract the low-dimensional features to be fed into a downstream model for gesture recognition. Wi-Learner introduces a novel meta-learner to "teach" the neural network to learn effectively from a small set of data points, allowing the base model to quickly adapt to a new domain using just one training sample. By so doing, we reduce the overhead of training data collection and allow a sensing system to adapt to the change of the deployed environment. We evaluate Wi-Learner by applying it to gesture recognition using the Widar 3.0 dataset. Extensive experiments demonstrate Wi-Learner is highly efficient and has a good generalization ability, by delivering an accuracy of 93.2% and 74.2% - 94.9% for in-domain and cross-domain using just one sample per gesture, respectively.
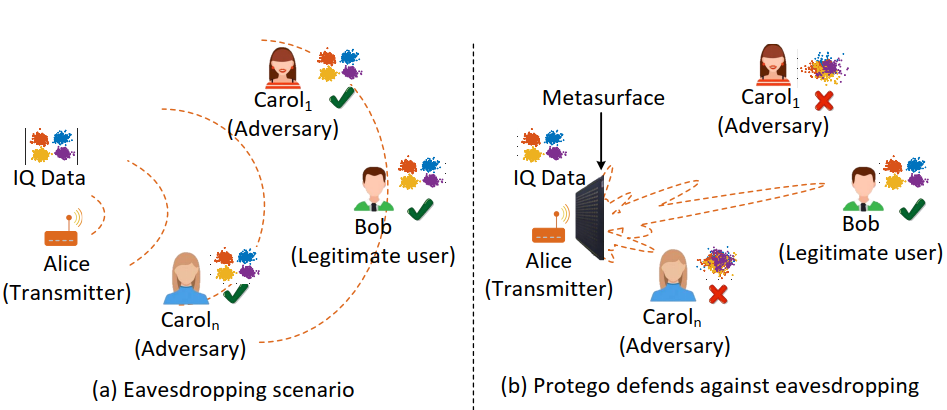
Protego: Securing Wireless Communication via Programmable Metasurface
Xinyi Li, Chao Feng, Fengyi Song, Chenghan Jiang, Yangfan Zhang, Ke Li, Xinyu Zhang, Xiaojiang Chen
MobiCom’22 (CCF-A) 2022
Phased array beamforming has been extensively explored as a physical layer primitive to improve the secrecy capacity of wireless communication links. However, existing solutions are incompatible with low-profile IoT devices due to cost, power and form factor constraints. More importantly, they are vulnerable to eavesdroppers with a high-sensitivity receiver. This paper presents Protego, which offloads the security protection to a metasurface comprised of a large number of 1-bit programmable unit-cells (i.e., phase shifters). Protego builds on a novel observation that, due to phase quantization effect, not all the unit-cells contribute equally to beamforming. By judiciously flipping the phase shift of certain unit-cells, Protego can generate artificial phase noise to obfuscate the signals towards potential eavesdroppers, while preserving the signal integrity and beamforming gain towards the legitimate receiver. A hardware prototype along with extensive experiments has validated the feasibility and effectiveness of Protego.
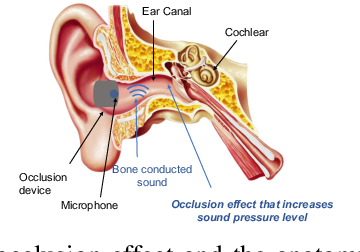
Earmonitor: In-ear Motion-resilient Acoustic Sensing using Commodity Earphones
Xue Sun, Jie Xiong, Chao Feng, Wenwen Deng, Xudong Wei, Dingyi Fang, Xiaojiang Chen
UbiComp’22 (CCF-A) 2022
Earphones are emerging as the most popular wearable devices and there has been a growing trend in bringing intelligence to earphones. Previous efforts include adding extra sensors (e.g., accelerometer and gyroscope) or peripheral hardware to make earphones smart. These methods are usually complex in design and also incur additional cost. In this paper, we present Earmonitor, a low-cost system that uses the in-ear earphones to achieve sensing purposes. The basic idea behind Earmonitor is that each person's ear canal varies in size and shape. We therefore can extract the unique features from the ear canal-reflected signals to depict the personalized differences in ear canal geometry. Furthermore, we discover that the signal variations are also affected by the fine-grained physiological activities. We can therefore further detect the subtle heartbeat from the ear canal reflections. Experiments show that Earmonitor can achieve up to 96.4% Balanced Accuracy (BAC) and low False Acceptance Rate (FAR) for user identification on a large-scale data of 120 subjects. For heartbeat monitoring, without any training, we propose signal processing schemes to achieve high sensing accuracy even in the most challenging scenarios when the target is walking or running.
RISE: Robust Wireless Sensing using Probabilistic and Statistical Assessments
Shuangjiao Zhai, Zhanyong Tang, Petteri Nurmi, Dingyi Fang, Xiaojiang Chen, Zheng Wang
MobiCom’21 (CCF-A) 2021
Wireless sensing builds upon machine learning shows encouraging results. However, adopting wireless sensing as a large-scale solution remains challenging as experiences from deployments have shown the performance of a machine-learned model to suffer when there are changes in the environment, e.g., when furniture is moved or when other objects are added or removed from the environment. We present Rise, a novel solution for enhancing the robustness and performance of learning-based wireless sensing techniques against such changes during a deployment. Rise combines probability and statistical assessments together with anomaly detection to identify samples that are likely to be misclassified and uses feedback on these samples to update a deployed wireless sensing model. We validate Rise through extensive empirical benchmarks by considering 11 representative sensing methods covering a broad range of wireless sensing tasks. Our results show that Rise can identify 92.3% of misclassifications on average. We showcase how Rise can be combined with incremental learning to help wireless sensing models retain their performance against dynamic changes in the operating environment to reduce the maintenance cost, paving the way for learning-based wireless sensing to become capable of supporting long-term monitoring in complex everyday environments.
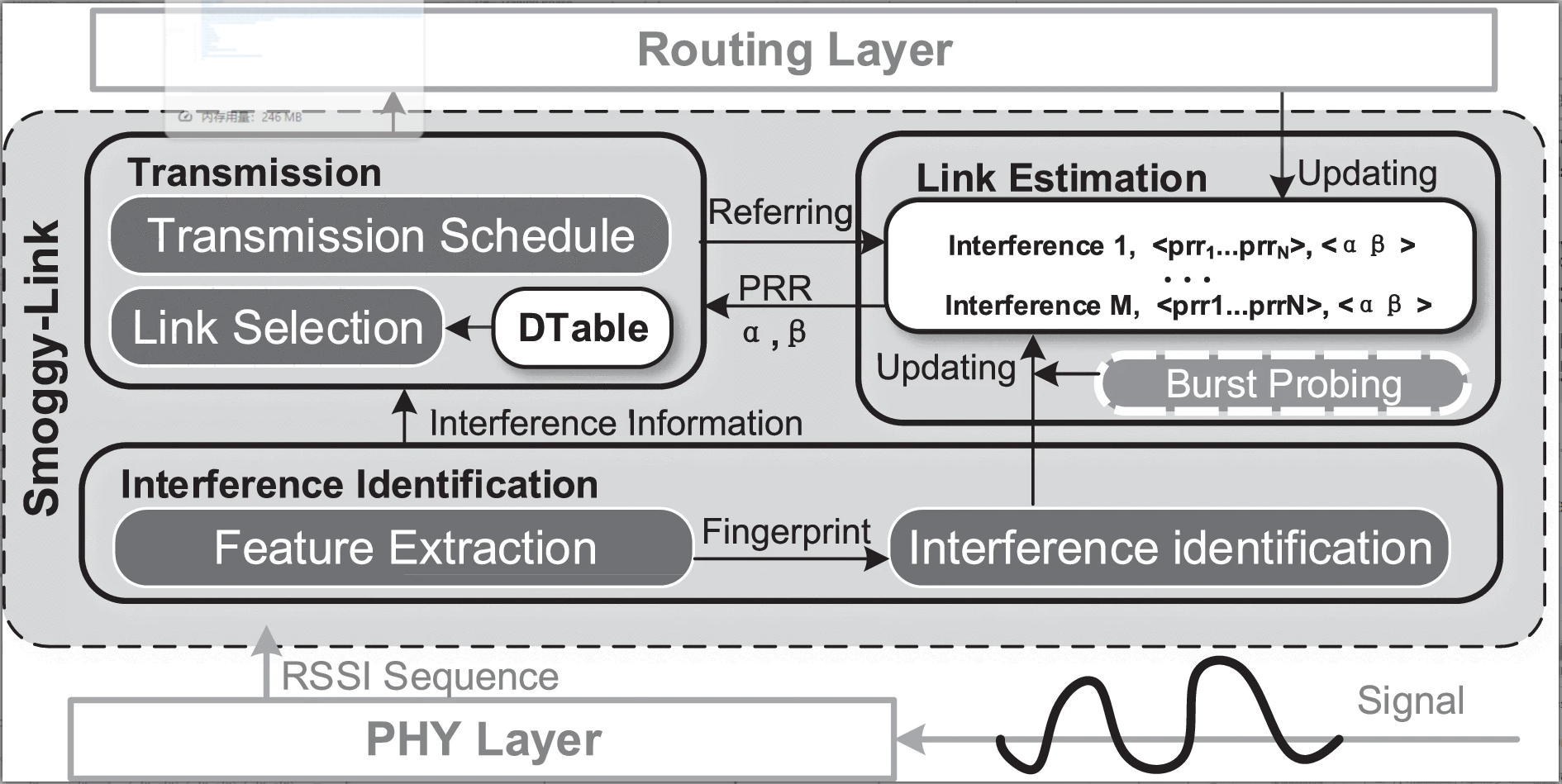
Exploiting Interference Fingerprints for Predictable Wireless Concurrency
Meng Jin, Yuan He, Xiaolong Zheng, Dingyi Fang, Dan Xu, Tianzhang Xing, Xiaojiang Chen
IEEE Transactions on Mobile Computing (CCF-A) 2021
Operating in unlicensed ISM bands, ZigBee devices often yield poor performance due to the interference from ever increasing wireless devices in the 2.4 GHz band. Our empirical results show that, a specific interference is likely to have different influence on different outbound links of a ZigBee sender, which indicates the chance of concurrent transmissions. Based on this insight, we propose Smoggy-Link, a practical protocol to exploit the potential concurrency for adaptive ZigBee transmissions under harsh interference. Smoggy-Link maintains an accurate link model to quantify and trace the relationship between interference and link qualities of the sender's outbound links. With such a link model, Smoggy-Link can translate low-cost interference information to the fine-grained spatiotemporal link state. The link information is further utilized for adaptive link selection and intelligent transmission schedule. We implement and evaluate a prototype of our approach with TinyOS and TelosB motes. The evaluation results show that Smoggy-Link has consistent improvements in both throughput and packet reception ratio under interference from various interferers.
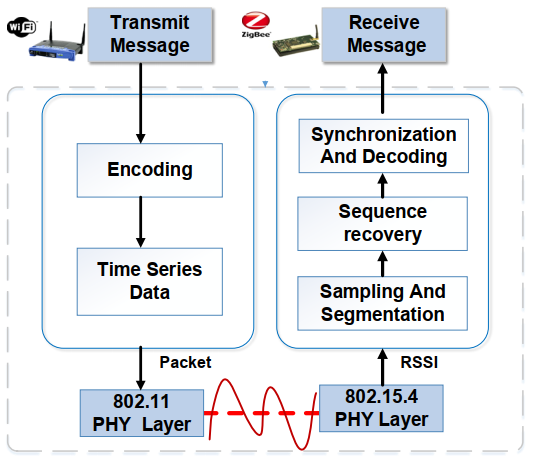
PRComm: Anti-Interference Cross-Technology Communication Based on Pseudo-random Sequence
Wei Wang, Dingsheng He, Wan Jia, Xiaojiang Chen, Tao Gu, Haiyan Liu, Xiaoyang Sun, Guannan Chen, Fuping Wu
IPSN '21 2021
With the rapid development of the Internet of Things (IoT), we have seen a larger number of devices deployed with different wireless communication protocols (i.e., WiFi, ZigBee, Bluetooth). Working in the same place opens a new opportunity for these devices to communicate directly with each other, leveraging on Cross-technology Communication (CTC). However, since these devices operate in the same frequency band which results in the competition against each other for network resources, severe interfere may arise. In this paper, we explore pseudo-random sequence (PR sequence) to design a novel CTC protocol that enables low-cost direct communication between WiFi and ZigBee in noisy indoor environments. Pseudorandom sequence offers a unique statistical feature to accomplish both information transmission and synchronization between heterogeneous devices. We design a dynamic synchronous decoding strategy to handle interference coexisted among different wireless protocols. Our system does not require any modification of communication protocol and underlying hardware and firmware. We implement our system on commercial devices (Intel 5300 WiFi NIC and MicaZ CC2420), and conduct extensive experiments to evaluate the system performance in three typical scenarios. The experimental results show that the synchronization time of our approach is lower than 0.5 ms, and the accuracy is greater than 84% while the channel occupancy is as high as 50%.
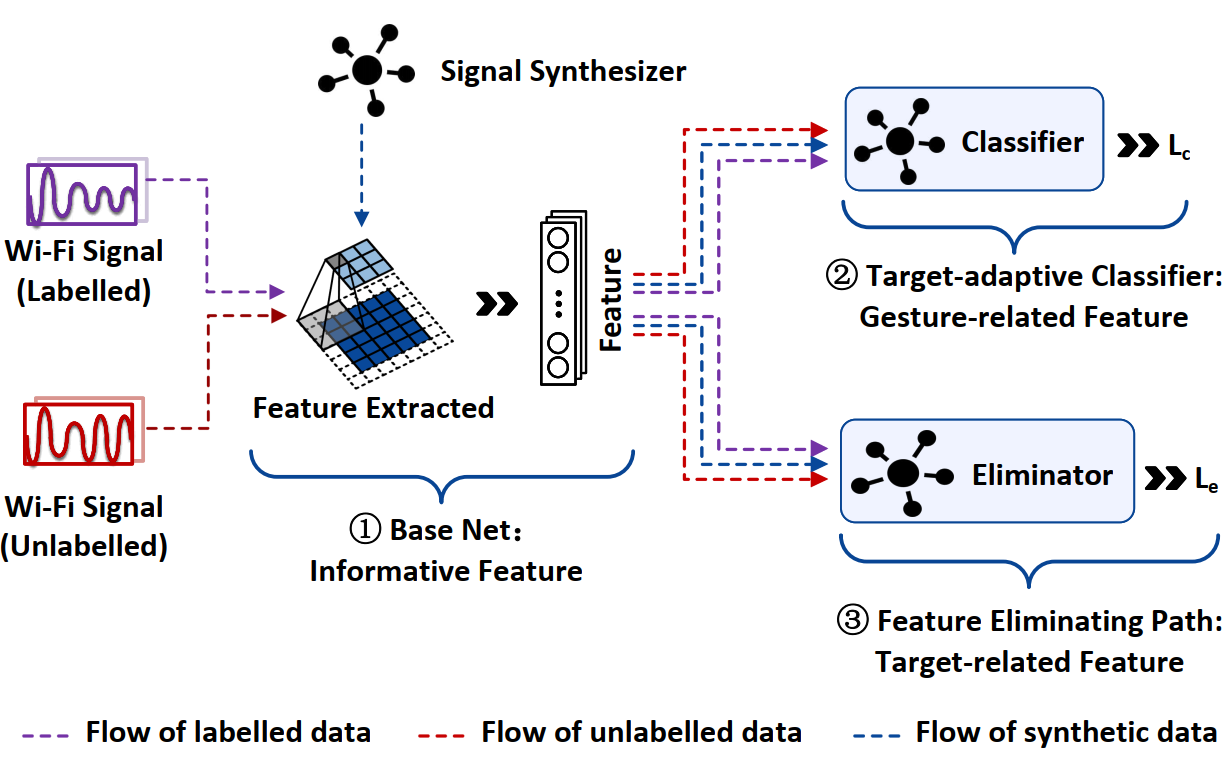
CrossGR: Accurate and Low-cost Cross-target Gesture Recognition Using Wi-Fi
Xinyi Li, Liqiong Chang, Fangfang Song, Ju Wang, Xiaojiang Chen, Zhanyong Tang, Zheng Wang
UbiComp’21 (CCF-A) 2021
This paper focuses on a fundamental question in Wi-Fi-based gesture recognition: "Can we use the knowledge learned from some users to perform gesture recognition for others?". This problem is also known as cross-target recognition. It arises in many practical deployments of Wi-Fi-based gesture recognition where it is prohibitively expensive to collect training data from every single user. We present CrossGR, a low-cost cross-target gesture recognition system. As a departure from existing approaches, CrossGR does not require prior knowledge (such as who is currently performing a gesture) of the target user. Instead, CrossGR employs a deep neural network to extract user-agnostic but gesture-related Wi-Fi signal characteristics to perform gesture recognition. To provide sufficient training data to build an effective deep learning model, CrossGR employs a generative adversarial network to automatically generate many synthetic training data from a small set of real-world examples collected from a small number of users. Such a strategy allows CrossGR to minimize the user involvement and the associated cost in collecting training examples for building an accurate gesture recognition system. We evaluate CrossGR by applying it to perform gesture recognition across 10 users and 15 gestures. Experimental results show that CrossGR achieves an accuracy of over 82.6% (up to 99.75%). We demonstrate that CrossGR delivers comparable recognition accuracy, but uses an order of magnitude less training samples collected from the end-users when compared to state-of-the-art recognition systems.
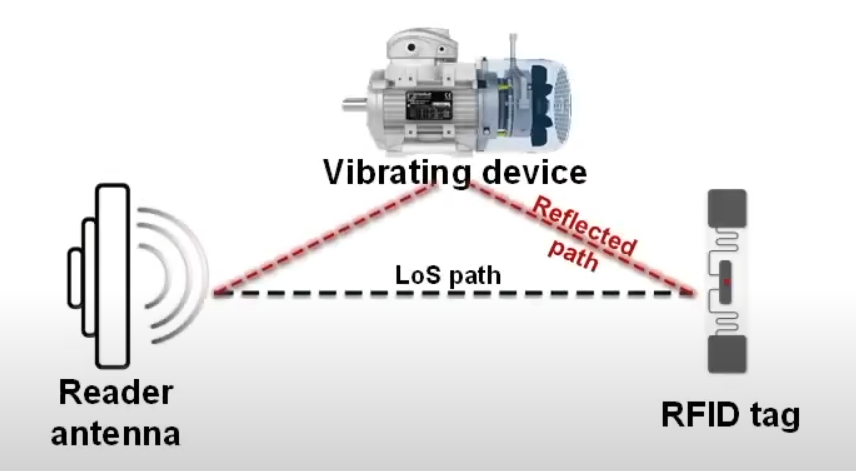
Exploring commodity RFID for contactless sub-millimeter vibration sensing
Binbin Xie, Jie Xiong, Xiaojiang Chen, Dingyi Fang
SenSys’20 (CCF-B) 2020
Monitoring the vibration characteristics of a machine or structure provides valuable information of its health condition and this information can be used to detect problems in their incipient stage. Recently, researchers employ RFID signals for vibration sensing. However, they mainly focus on vibration frequency estimation and still face difficulties in accurately sensing the other important characteristic of vibration which is vibration amplitude in the scale of sub-millimeter. In this paper, we introduce TagSMM, a contactless RFID-based vibration sensing system which can measure vibration amplitude in sub-millimeter resolution. TagSMM employs the signal propagation theory to deeply understand how the signal phase varies with vibration and proposes a coupling-based method to amplify the vibration-induced phase change to achieve sub-millimeter level amplitude sensing for the first time. We design and implement TagSMM with commodity RFID hardware. Our experiments show that TagSMM can detect a 0.5 mm vibration, 10 times better than the state-of-the-arts. Our field studies show TagSMM can sense a drone's abnormal vibration and can also effectively detect a small 0.2 cm screw loose in a motor at a 100% accuracy.

WideSee: Towards Wide-Area Contactless Wireless Sensing
Lili Chen, Jie Xiong, Xiaojiang Chen, Sunghoon Ivan Lee, Kai Chen, Dianhe Han, Dingyi Fang, Zhanyong Tang, Zheng Wang
SenSys’19 (CCF-B) (Best Paper Award Candidates) 2020
Contactless wireless sensing without attaching a device to the target has achieved promising progress in recent years. However, one severe limitation is the small sensing range. This paper presents WideSee to realize wide-area sensing with only one transceiver pair. WideSee utilizes the LoRa signal to achieve a larger range of sensing and further incorporates drone's mobility to broaden the sensing area. WideSee presents solutions across software and hardware to overcome two aspects of challenges for wide-range contactless sensing: (i) the interference brought by the device mobility and LoRa's high sensitivity; and (ii) the ambiguous target information such as location when employing just a single pair of transceivers. We have developed a working prototype of WideSee for human target detection and localization that are especially useful in emergency scenarios such as rescue search, and evaluated WideSee with both controlled experiments and the field study in a high-rise building. Extensive experiments demonstrate the great potential of WideSee for wide-area contactless sensing with a single LoRa transceiver pair hosted on a drone.
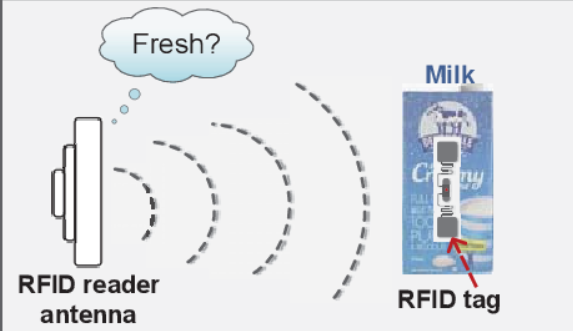
Tagtag: Material Sensing with Commodity RFID
Binbin Xie, Jie Xiong, Xiaojiang Chen, Eugene Chai, Liyao Li, Zhanyong Tang, Dingyi Fang
SenSys’19 (CCF-B) 2019
Material sensing is an essential ingredient for many IoT applications. While hyperspectral camera, infrared, X-Ray, and Radar provide potential solutions for material identification, high cost is the major concern limiting their applications. In this paper, we explore the capability of employing RF signals for fine-grained material sensing with commodity RFID device. The key reason for our system to work is that the tag antenna's impedance is changed when it is close or attached to a target. The amount of impedance change is dependent on the target's material type, thus enabling us to utilize the impedance-related phase change available at commodity RFID devices for material sensing. Several key challenges are addressed before we turn the idea into a functional system: (i) the random tag-reader distance causes an additional unknown phase change on top of the phase change caused by the target material; (ii) the tag rotations cause phase shifts and (iii) for conductive liquid, there exists liquid reflection which interferes with the impedance-caused phase change. We address these challenges with novel solutions. Comprehensive experiments show high identification accuracies even for very similar materials such as Pepsi and Coke.
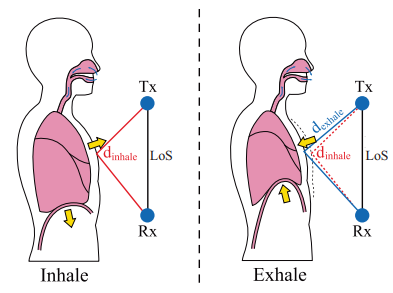
LungTrack: Towards Contactless and Zero Dead-Zone Respiration Monitoring with Commodity RFIDs
Lili Chen, Jie Xiong, Xiaojiang Chen, Sunghoon Ivan Lee, Tao Yan, Dingyi Fang
UbiComp’19 (CCF-A) 2019
Respiration rate sensing plays a critical role in elderly care and patient monitoring. The latest research has explored the possibility of employing Wi-Fi signals for respiration sensing without attaching a device to the target. A critical issue with these solutions includes that good monitoring performance could only be achieved at certain locations within the sensing range, while the performance could be quite poor at other "dead zones." In addition, due to the contactless nature, it is challenging to monitor multiple targets simultaneously as the reflected signals are often mixed together. In this work, we present our system, named LungTrack, hosted on commodity RFID devices for respiration monitoring. Our system retrieves subtle signal fluctuations at the receiver caused by chest displacement during respiration without need for attaching any devices to the target. It addresses the dead-zone issue and enables simultaneous monitoring of two human targets by employing one RFID reader and carefully positioned multiple RFID tags, using an optimization technique. Comprehensive experiments demonstrate that LungTrack can achieve a respiration monitoring accuracy of greater than 98% for a single target at all sensing locations (within 1st -- 5th Fresnel zones) using just one RFID reader and five tags, when the target's orientation is known a priori. For the challenging scenario involve two human targets, LungTrack is able to achieve greater than 93% accuracy when the targets are separated by at least 10 cm.
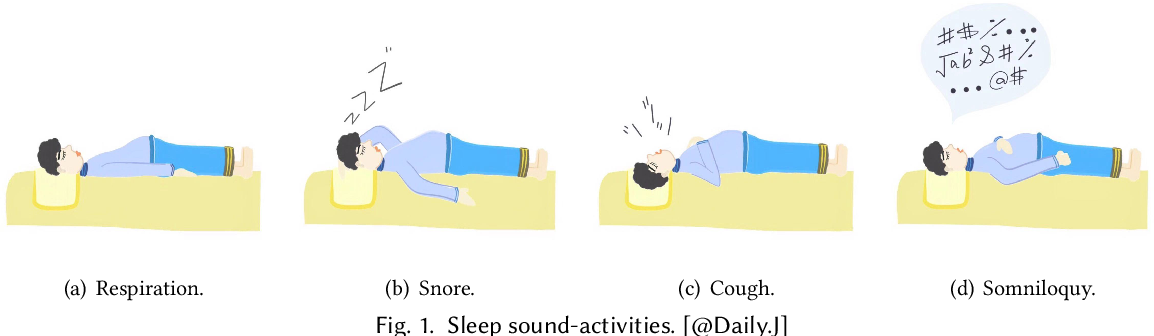
Beyond Respiration: Contactless Sleep Sound Activity Recognition Using RF Signals
Chen Liu, Jie Xiong, Lin Cai, Lin Feng, Xiaojiang Chen, Dingyi Fang
UbiComp’19 (CCF-A) 2019
Sleep sound-activities including snore, cough and somniloquy are closely related to sleep quality, sleep disorder and even illnesses. To obtain the information of these activities, current solutions either require the user to wear various sensors/devices, or use the camera/microphone to record the image/sound data. However, many people are reluctant to wear sensors/devices during sleep. The video-based and audio-based approaches raise privacy concerns. In this work, we propose a novel system TagSleep to address the issues mentioned above. For the first time, we propose the concept of two-layer sensing. We employ the respiration sensing information as the basic first-layer information, which is applied to further obtain rich second-layer sensing information including snore, cough and somniloquy. Specifically, without attaching any device to the human body, by just deploying low-cost and flexible RFID tags near to the user, we can accurately obtain the respiration information. What's more interesting, the user's cough, snore and somniloquy all affect his/her respiration, so the fine-grained respiration changes can be used to infer these sleep sound-activities without recording the sound data. We design and implement our system with just three RFID tags and one RFID reader. We evaluate the performance of TagSleep with 30 users (13 males and 17 females) for a period of 2 months. TagSleep is able to achieve higher than 96.58% sensing accuracy in recognizing snore, cough and somniloquy under various sleep postures. TagSleep also boosts the sleep posture recognition accuracy to 98.94%.
WiMi: Target Material Identification with Commodity Wi-Fi Devices
Chao Feng, Jie Xiong, Liqiong Chang, Ju Wang, Xiaojiang Chen, Dingyi Fang, Zhanyong Tang
ICDCS’19 (CCF-B) 2019
Target material identification is playing an important role in our everyday life. Traditional camera and video-based methods bring in severe privacy concerns. In the last few years, while RF signals have been exploited for indoor localization, gesture recognition and motion tracking, very little attention has been paid in material identification. This paper introduces WiMi, a device-free target material identification system, implemented on ubiquitous and cheap commercial off-the-shelf (COTS) Wi-Fi devices. The intuition is that different materials produce different amounts of phase and amplitude changes when a target appears on the line-of-sight (LoS) of a radio frequency (RF) link. However, due to multipath and hardware imperfection, the measured phase and amplitude of the channel state information (CSI) are very noisy. We thus present novel CSI pre-processing schemes to address the multipath and hardware noise issues before they can be used for accurate material sensing. We also design a new material feature which is only related to the material type and is independent of the target size. Comprehensive real-life experiments demonstrate that WiMi can achieve fine-grained material identification with cheap commodity Wi-Fi devices. WiMi can identify 10 commonly seen liquids at an overall accuracy higher than 95% with strong multipath indoors. Even for very similar items such as Pepsi and Coke, WiMi can still differentiate them at a high accuracy.
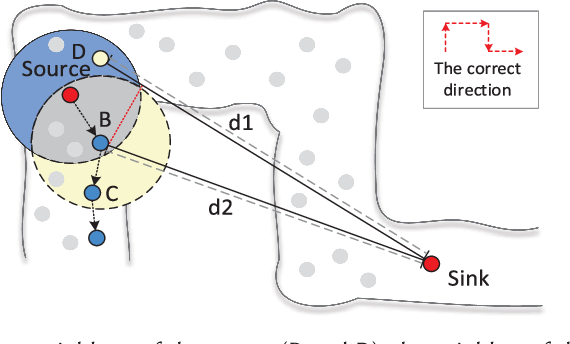
Low-Cost and Robust Geographic Opportunistic Routing in a Strip Topology Wireless Network
Chen Liu, Dingyi Fang, Xinyan Liu, Dan Xu, Xiaojiang Chen, Chieh-Jan Mike Liang, Baoying Liu, Zhanyong Tang
ACM Transactions on Sensor Networks (CCF-B) 2019
Wireless sensor networks (WSNs) have been used for many long-term monitoring applications with the strip topology that is ubiquitous in the real-world deployment, such as pipeline monitoring, water quality monitoring, vehicle monitoring, and Great Wall monitoring. The efficiency of routing strategy has been playing a key role in serving such monitoring applications. In this article, we first present a robust geographic opportunistic routing (GOR) approach—LIght Propagation Selection (LIPS)—that can provide a short path with low energy consumption, communication overhead, and packet loss. To overcome the complication caused by the multi-turning point structure, we propose the virtual Plane mirror (VPM) algorithm, inspired by the light propagation, which is to map the strip topology into the straight one logically. We then select partial neighbors as the candidates to avoid blindly involving all next-hop neighbors and ensure the data transmission along the correct direction. Two implementation problems of VPM—transmission spread angle and the communication range—are thoroughly analyzed based on the percolation theory. Based on the preceding candidate selection algorithms, we propose a GOR algorithm in the strip topology network. By theoretical analysis and extensive simulation, we illustrate the validity and higher transmission performance of LIPS in strip WSNs. In addition, we have proved that the length of the path in LIPS is two times the length of the shortest path via geometrical analysis. Simulation results show that the transmission success rate of our approach is 26.37% higher than the state-of-the-art approach, and the communication overhead and energy consumption rate are 33.11% and 40.23% lower, respectively.

FlipTracer: Practical Parallel Decoding for Backscatter Communication
Meng Jin, Yuan He, Xin Meng, Yilun Zheng, Dingyi Fang, Xiaojiang Chen
IEEE/ACM Transactions on Networking (CCF-A) 2019
With parallel decoding for backscatter communication, tags are allowed to transmit concurrently and more efficiently. Existing parallel decoding mechanisms, however, assume that signals of the tags are highly stable and, hence, may not perform optimally in the naturally dynamic backscatter systems. This paper introduces FlipTracer, a practical system that achieves highly reliable parallel decoding even in hostile channel conditions. FlipTracer is designed with a key insight; although the collided signal is time-varying and irregular, transitions between signals' combined states follow highly stable probabilities, which offers important clues for identifying the collided signals and provides us with an opportunity to decode the collided signals without relying on stable signals. Motivated by this observation, we propose a graphical model, called one-flip-graph (OFG), to capture the transition pattern of collided signals, and design a reliable approach to construct the OFG in a manner robust to the diversity in backscatter systems. Then, FlipTracer can resolve the collided signals by tracking the OFG. We have implemented FlipTracer and evaluated its performance with extensive experiments across a wide variety of scenarios. Our experimental results have shown that FlipTracer achieves a maximum aggregated throughput that approaches 2 Mb/s, which is 6× higher than the state of the art.
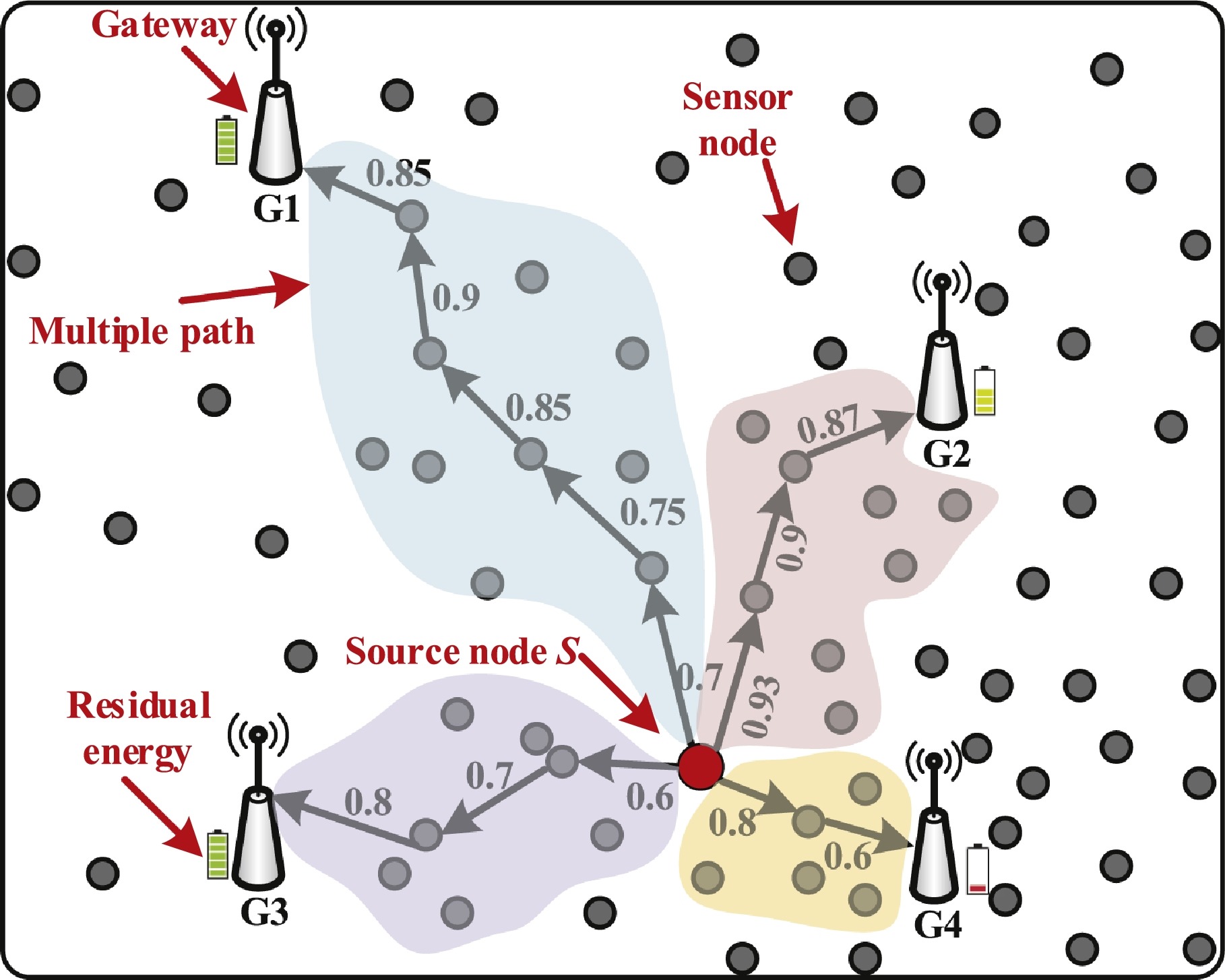
Enabling robust and reliable transmission in Internet of Things with multiple gateways
Dan Xu, Wenli Jiao, Zhuang Yin, Bin Wu, Yao Peng, Xiaojiang Chen#, Feng Chen, Dingyi Fang
Computer Networks (CCF-B) 2018
This paper investigates the robust and reliable transmission problem in Internet of Things (IoT) applications, where multiple gateways are deployed. We discover that the reliable routing path with the best link qualities may not always gain the reliable transmission. The main reason is that the majority of existing routing metrics generally do not consider the working state of gateways. And the gateways may significantly reduce the reliability of data transmission at the last hop when they operate at the variable duty cycles (e.g., due to insufficient energy harvesting from ambiance). Last-hop data loss will lead to the inefficient transmission in all previous hops. To address this issue, we propose a novel routing metric ETD (Expected Transmission Direction, ETD), which efficiently selects a proper set of gateways with improved reliability in variable duty-cycled IoT through estimating the working state of gateways. Based on ETD, we design an efficient opportunistic routing protocol PoR to ensure reliable data transmission. Our simulations demonstrate the superior performance of PoR. It is shown that PoR achieves over 98% packet delivery ratio even in the worst network setting, with effective load balancing among selected gateways.
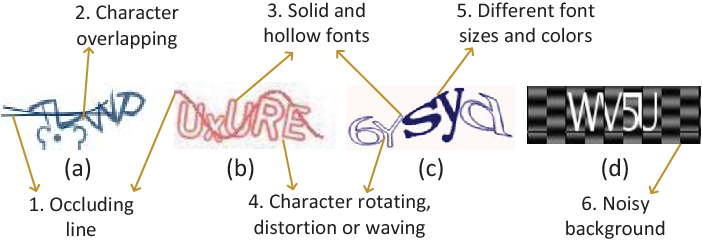
Yet Another Text Captcha Solver: A Generative Adversarial Network Based Approach
Guixin Ye, Zhanyong Tang, Dingyi Fang, Zhanxing Zhu, Yansong Feng, Pengfei Xu, Xiaojiang Chen, Zheng Wang
CCS’18 2018
Despite several attacks have been proposed, text-based CAPTCHAs are still being widely used as a security mechanism. One of the reasons for the pervasive use of text captchas is that many of the prior attacks are scheme-specific and require a labor-intensive and time-consuming process to construct. This means that a change in the captcha security features like a noisier background can simply invalid an earlier attack. This paper presents a generic, yet effective text captcha solver based on the generative adversarial network. Unlike prior machine-learning-based approaches that need a large volume of manually-labeled real captchas to learn an effective solver, our approach requires significantly fewer real captchas but yields much better performance. This is achieved by first learning a captcha synthesizer to automatically generate synthetic captchas to learn a base solver, and then fine-tuning the base solver on a small set of real captchas using transfer learning. We evaluate our approach by applying it to 33 captcha schemes, including 11 schemes that are currently being used by 32 of the top-50 popular websites including Microsoft, Wikipedia, eBay and Google. Our approach is the most capable attack on text captchas seen to date. It outperforms four state-of-the-art text-captcha solvers by not only delivering a significant higher accuracy on all testing schemes, but also successfully attacking schemes where others have zero chance. We show that our approach is highly efficient as it can solve a captcha within 0.05 second using a desktop GPU. We demonstrate that our attack is generally applicable because it can bypass the advanced security features employed by most modern text captcha schemes. We hope the results of our work can encourage the community to revisit the design and practical use of text captchas.
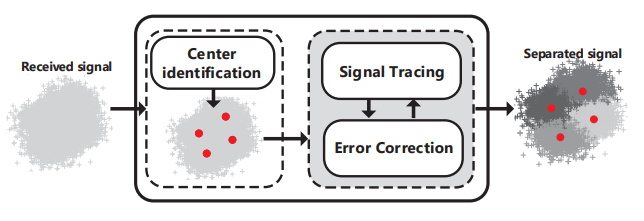
Parallel Backscatter in the Wild: When Burstiness and Randomness Play with You
Meng Jin, Dingyi Fang, Yuan He, Xin Meng, Xiaojiang Chen
MobiCom’18 (CCF-A) 2018
Parallel backscatter is a promising technique for high throughput, low power communications. The existing approaches of parallel backscatter are based on a common assumption, i.e. the states of the collided signals are distinguishable from each other in either the time domain or the IQ (the In-phase and Quadrature) domain. We in this paper disclose the superclustering phenomenon, which invalidates that assumption and seriously affects the decoding performance. Then we propose an interstellar travelling model to capture the bursty Gaussian process of a collided signal. Based on this model, we design Hubble, a reliable signal processing approach to support parallel backscatter in the wild. Hubble addresses several technical challenges: (i) a novel scheme based on Pearson's Chi-Square test to extract the collided signals' combined states, (ii) a Markov driven method to capture the law of signal state transitions, and (iii) error correction schemes to guarantee the reliability of parallel decoding. Theoretically, Hubble is able to decode all the backscattered data, as long as the signals are detectable by the receiver. The experiment results demonstrate that the median throughput of Hubble is $11.7times$ higher than that of the state-of-the-art approach.
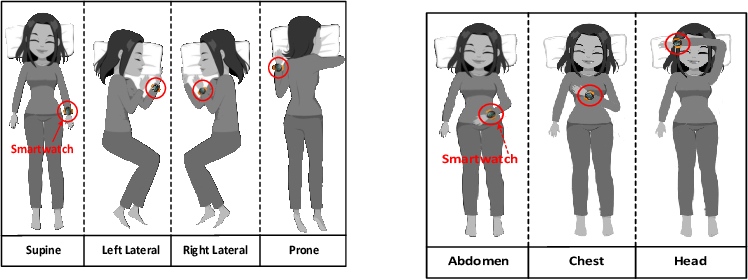
SleepGuard: Capturing Rich Sleep Information Using Smartwatch Sensing Data
Liqiong Chang, Jiaqi Lu, Ju Wang, Xiaojiang Chen, Dingyi Fang, Zhanyong Tang, Petteri Nurmi, Zheng Wang
Ubicomp’18 (CCF-A) 2018
Sleep is an important part of our daily routine -- we spend about one-third of our time doing it. By tracking sleep-related events and activities, sleep monitoring provides decision support to help us understand sleep quality and causes of poor sleep. Wearable devices provide a new way for sleep monitoring, allowing us to monitor sleep from the comfort of our own home. However, existing solutions do not take full advantage of the rich sensor data provided by these devices. In this paper, we present the design and development of SleepGuard, a novel approach to track a wide range of sleep-related events using smartwatches. We show that using merely a single smartwatch, it is possible to capture a rich amount of information about sleep events and sleeping context, including body posture and movements, acoustic events, and illumination conditions. We demonstrate that through these events it is possible to estimate sleep quality and identify factors affecting it most. We evaluate our approach by conducting extensive experiments involved fifteen users across a 2-week period. Our experimental results show that our approach can track a richer set of sleep events, provide better decision support for evaluating sleep quality, and help to identify causes for sleep problems compared to prior work.
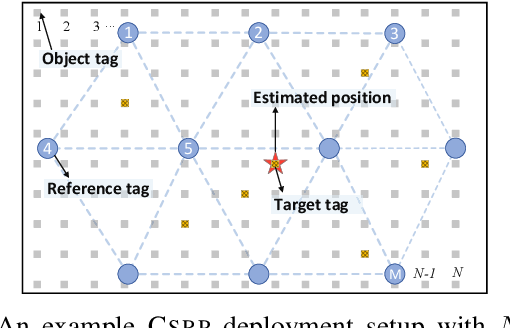
Towards Large-Scale RFID Positioning: A Low-cost, High-precision Solution Based on Compressive Sensing
Liqiong Chang, Xinyi li, Ju Wang, Haining Meng, Xiaojiang Chen, Dingyi Fang, Zhanyong Tang, Zheng Wang
PerCom’18 (CCF-B) 2018
RFID-based positioning is emerging as a promising solution for inventory management in places like warehouses and libraries. However, existing solutions either are too sensitive to the environmental noise, or require deploying a large number of reference tags which incur expensive deployment cost and increase the chance of data collisions. This paper presents CSRP, a novel RFID based positioning system, which is highly accurate and robust to environmental noise, but relies on much less reference tags compared with the state-of-the-art. CSRP achieves this by employing an noise-resilient RFID fingerprint scheme and a compressive sensing based algorithm that can recover the target tag's position using a small number of signal measurements. This work provides a set of new analysis, algorithms and heuristics to guide the deployment of reference tags and to optimize the computational overhead. We evaluate CSRP in a deployment site with 270 commercial RFID tags. Experimental results show that CSRP can correctly identify 84.7% of the test items, achieving an accuracy that is comparable to the state-of-the-art, using an order of magnitude less reference tags.
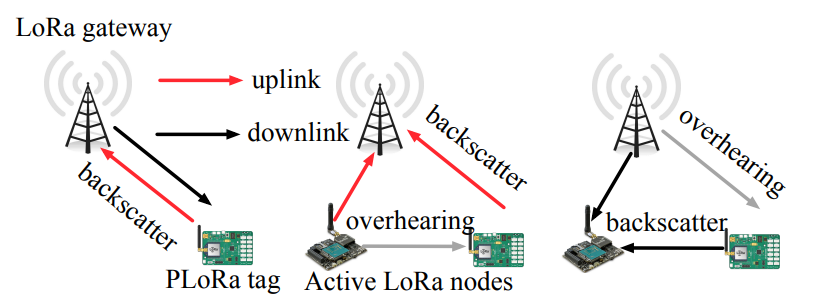
PLoRa: a passive long-range data network from ambient LoRa transmissions
Yao Peng, Longfei Shangguan, Yue Hu, Yujie Qian, Xianshang Lin, Xiaojiang Chen, Dingyi Fang, Kyle Jamieson
Sigcomm’18 (CCF-A) 2018
This paper presents PLoRa, an ambient backscatter design that enables long-range wireless connectivity for batteryless IoT devices. PLoRa takes ambient LoRa transmissions as the excitation signals, conveys data by modulating an excitation signal into a new standard LoRa "chirp" signal, and shifts this new signal to a different LoRa channel to be received at a gateway faraway. PLoRa achieves this by a holistic RF front-end hardware and software design, including a low-power packet detection circuit, a blind chirp modulation algorithm and a low-power energy management circuit. To form a complete ambient LoRa backscatter network, we integrate a light-weight backscatter signal decoding algorithm with a MAC-layer protocol that work together to make coexistence of PLoRa tags and active LoRa nodes possible in the network. We prototype PLoRa on a four-layer printed circuit board, and test it in various outdoor and indoor environments. Our experimental results demonstrate that our prototype PCB PLoRa tag can backscatter an ambient LoRa transmission sent from a nearby LoRa node (20 cm away) to a gateway up to 1.1 km away, and deliver 284 bytes data every 24 minutes indoors, or every 17 minutes outdoors. We also simulate a 28-nm low-power FPGA based prototype whose digital baseband processor achieves 220 μW power consumption.
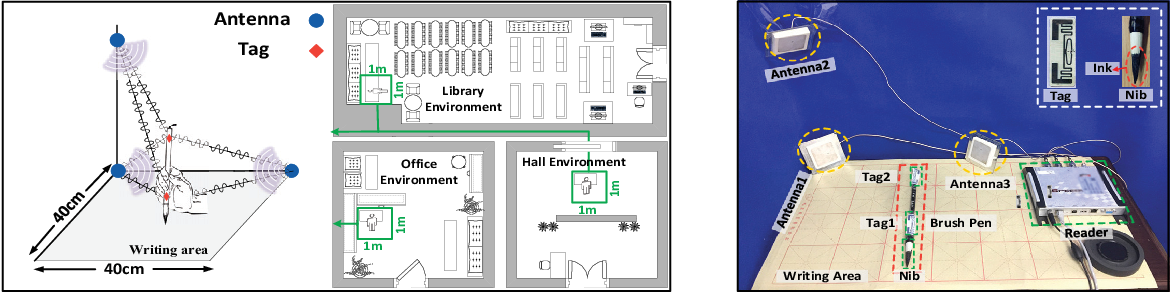
Evaluating Brush Movements for Chinese Calligraphy: A Computer Vision Based Approach
Pengfei Xu, Lei Wang, Ziyu Guan, Xia Zheng, Xiaojiang Chen, Zhanyong Tang, Dingyi Fang, Xiaoqing Gong, Zheng Wang
IJCAI’18 2018
Chinese calligraphy is a popular, highly esteemed art form in the Chinese cultural sphere and worldwide. Ink brushes are the traditional writing tool for Chinese calligraphy and the subtle nuances of brush movements have a great impact on the aesthetics of the written characters. However, mastering the brush movement is a challenging task for many calligraphy learners as it requires many years’ practice and expert supervision. This paper presents a novel approach to help Chinese calligraphy learners to quantify the quality of brush movements without expert involvement. Our approach extracts the brush trajectories from a video stream; it then compares them with example templates of reputed calligraphers to produce a score for the writing quality. We achieve this by first developing a novel neural network to extract the spatial and temporal movement features from the video stream. We then employ methods developed in the computer vision and signal processing domains to track the brush movement trajectory and calculate the score. We conducted extensive experiments and user studies to evaluate our approach. Experimental results show that our approach is highly accurate in identifying brush movements, yielding an average accuracy of 90%, and the generated score is within 3% of errors when compared to the one given by human experts.
Maximizing throughput for low duty-cycled sensor networks
Meng Jin, Yuan He, Dingyi Fang, Xiaojiang Chen, Tianzheng Xing
IEEE Transactions on Mobile Computing (CCF-A) 2018
Smartphone theft is a non-negligible problem that causes serious concerns on personal property and privacy. The existing solutions to this problem either provide only functions like retrieving a phone, or require dedicated hardware to detect thefts. How to protect smartphones from being stolen at all times is still an open problem. In this paper, we propose iGuard, a real-time anti-theft system for smartphones. iGuard utilizes only the inertial sensing data from the smartphone. The basic idea behind iGuard is to distinguish different people holding a smartphone, by identifying the order of the motions during the `take-out' behavior and how each motion is performed. For this purpose, we design a motion segmentation algorithm to detect the transition between two motions from the noisy sensing data. We then leverage the distinct feature contained in each sub-segment of a motion to estimate the probability that the motion is performed by the smartphone owner himself/herself. Based on such pre-processed data, we propose a Markov based model to track the behavior of a smartphone user. According to this model, iGuard instantly alarms once the tracked data deviate from the smartphone owner's usual habit. We implement iGuard on Android and evaluate its performance in real environments. The experimental results show that iGuard is accurate and robust in various scenarios.
RF-Copybook: A Millimeter Level Calligraphy Copybook based on commodity RFID
Liqiong Chang, Jie Xiong, Ju Wang, Xiaojiang Chen, Yu Wang, Zhanyong Tang, Dingyi Fang
Ubicomp’18 (CCF-A) 2018
As one of the best ways to learn and appreciate the Chinese culture, Chinese calligraphy is widely practiced and learned all over the world. Traditional calligraphy learners spend a great amount of time imitating the image templates of reputed calligraphers. In this paper, we propose an RF-based Chinese calligraphy template, named RF-Copybook, to precisely monitor the writing process of the learner and provide detail instructions to improve the learner's imitating behavior. With two RFID tags attached on the brush pen and three antennas equipped at the commercial RFID reader side, RF-Copybook tracks the pen's 3-dimensional movements precisely. The key intuition behind RF-Copybook's idea is that: (i) when there is only direct path signal between the tag and the antenna, the phase measured at the reader changes linearly with the distance, (ii) the reader offers very fine-grained phase readings, thus a millimeter level accuracy of antenna-tag distance can be obtained, (iii) by combing multiple antenna-tag distances, we can quantify the writing process with stroke based feature models. Extensive experiments show that RF-Copybook is robust against the environmental noise and achieves high accuracies across different environments in the estimation of the brush pen's elevation angle, nib's moving speed and position.
Cracking Android Pattern Lock in Five Attempts
Guixin Ye, Zhanyong Tang, Dingyi Fang, Xiaojiang Chen, Kwang In Kim, Ben Taylor, Zheng Wang
NDSS’17 (CCF-B) 2017
Pattern lock is widely used as a mechanism for authentication and authorization on Android devices. In this paper, we demonstrate a novel video-based attack to reconstruct Android lock patterns from video footage filmed using a mobile phone camera. Unlike prior attacks on pattern lock, our approach does not require the video to capture any content displayed on the screen. Instead, we employ a computer vision algorithm to track the fingertip movements to infer the pattern. Using the geometry information extracted from the tracked fingertip motions, our approach is able to accurately identify a small number of (often one) candidate patterns to be tested by an adversary. We thoroughly evaluated our approach using 120 unique patterns collected from 215 independent users, by applying it to reconstruct patterns from video footage filmed using smartphone cameras. Experimental results show that our approach can break over 95% of the patterns in five attempts before the device is automatically locked by the Android system. We discovered that, in contrast to many people s belief, complex patterns do not offer stronger protection under our attacking scenarios. This is demonstrated by the fact that we are able to break all but one complex patterns (with a 97.5% success rate) as opposed to 60% of the simple patterns in the first attempt. Since our threat model is common in day-to-day lives, our workr calls for the community to revisit the risks of using Android pattern lock to protect sensitive information.
iGuard: A Real-Time Anti-Theft System for Smartphones
Meng jin, He yuan, Dingyi Fang, Xiaojiang Chen, Xin Meng, Tianzhang Xing
INFOCOM’17 2017
Smartphone theft is a non-negligible problem that causes serious concerns on personal property, privacy, and public security. The existing solutions to this problem either provide only functions like retrieving a phone, or require dedicated hardware to detect thefts. How to protect smartphones from being stolen at all times is still an open problem. In this paper, we propose iGuard, a real-time anti-theft system for smartphones. iGuard utilizes only the inertial sensing data from the smartphone. The basic idea behind iGuard is to distinguish different people holding a smartphone, by identifying the order of the motions during the ‘take-out’ behavior and how each motion is performed. For this purpose, we design a motion segmentation algorithm to detect the transition between two motions from the noisy sensing data. We then leverage the distinct feature contained in each sub-segment of a motion, instead of the entire motion, to estimate the probability that the motion is performed by the smartphone owner himself/herself. Based on such pre-processed data, we propose a Markov Chain based model to track the behavior of a smartphone user. According to this model, iGuard instantly alarms once the tracked data deviate from the smartphone owner's usual habit. We implement iGuard on Android and evaluate its performance in real environments. The experimental results show that iGuard is accurate and robust in various scenarios.
iUpdater: Low-Cost RSS Fingerprints Updating for Device-Free Localization
Liqiong Chang, Jie Xiong, Yu Wang, Xiaojiang Chen, Junhao Hu, Dingyi Fang
ICDCS’17 (CCF-B) 2017
While most existing indoor localization techniques are device-based, many emerging applications such as intruder detection and elderly monitoring drive the needs of device-free localization, in which the target can be localized without any device attached. Among the diverse techniques, received signal strength (RSS) fingerprint-based methods are popular because of the wide availability of RSS readings in most commodity hardware. However, current fingerprint-based systems suffer from high human labor cost to update the fingerprint database and low accuracy due to the large degree of RSS variations. In this paper, we propose a fingerprint-based device-free localization system named iUpdater to significantly reduce the labor cost and increase the accuracy. We present a novel self-augmented regularized singular value decomposition (RSVD) method integrating the sparse attribute with unique properties of the fingerprint database. iUpdater is able to accurately update the whole database with RSS measurements at a small number of reference locations, thus reducing the human labor cost. Furthermore, iUpdater observes that although the RSS readings vary a lot, the RSS differences between both the neighboring locations and adjacent wireless links are relatively stable. This unique observation is applied to overcome the short-term RSS variations to improve the localization accuracy. Extensive experiments in three different environments over 3 months demonstrate the effectiveness and robustness of iUpdater.
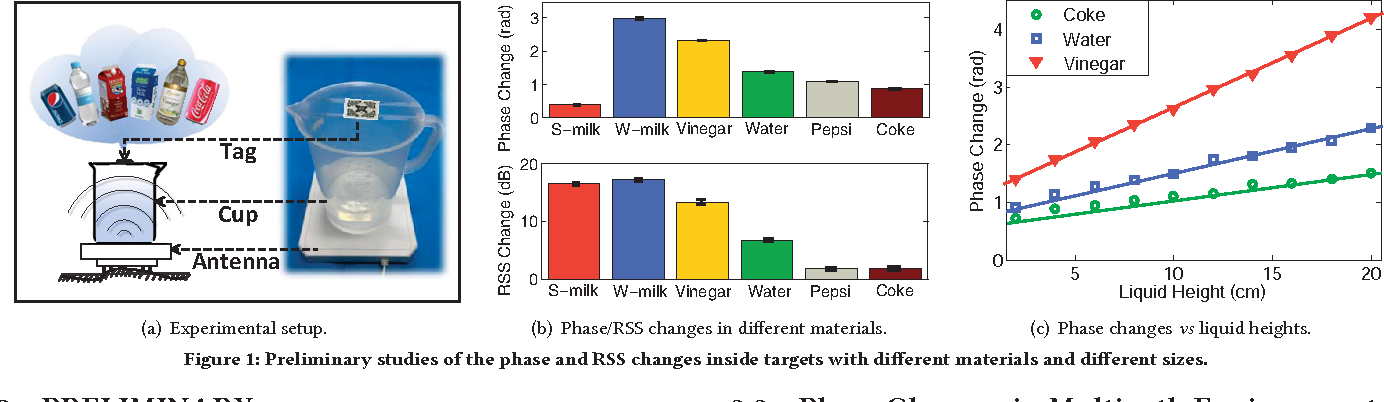
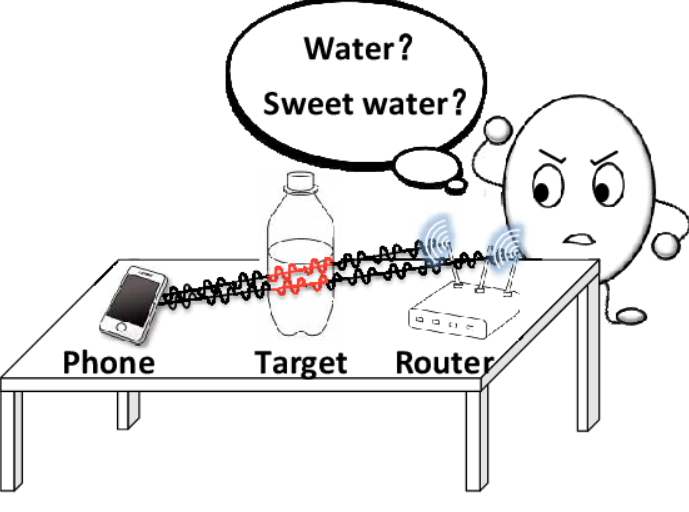
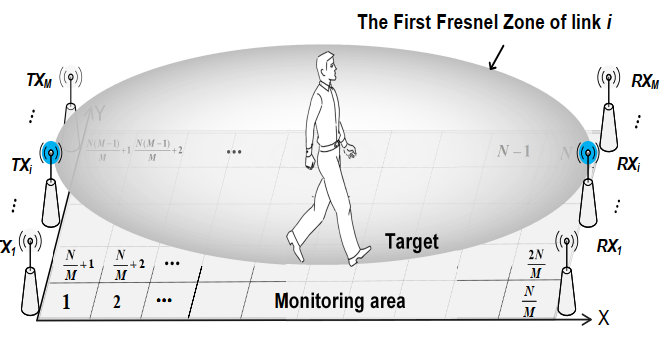
TagScan: Simultaneous Target Imaging and Material Identification with Commodity RFID Devices
Ju Wang, Jie Xiong, Xiaojiang Chen, Hongbo Jiang, Rajesh Krishna Balan, Dingyi Fang
MobiCom’17 (CCF-A) 2017
Target imaging and material identification play an important role in many real-life applications. This paper introduces TagScan, a system that can identify the material type and image the horizontal cut of a target simultaneously with cheap commercial off the-shelf (COTS) RFID devices. The key intuition is that different materials and target sizes cause different amounts of phase and RSS (Received Signal Strength) changes when radio frequency (RF) signal penetrates through the target. Multiple challenges need to be addressed before we can turn the idea into a functional system including (i) indoor environments exhibit rich multipath which breaks the linear relationship between the phase change and the propagation distance inside a target; (ii) without knowing either material type or target size, trying to obtain these two information simultaneously is challenging; and (iii) stitching pieces of the propagation distances inside a target for an image estimate is non-trivial. We propose solutions to all the challenges and evaluate the system's performance in three different environments. TagScan is able to achieve higher than 94% material identification accuracies for 10 liquids and differentiate even very similar objects such as Coke and Pepsi. TagScan can accurately estimate the horizontal cut images of more than one target behind a wall.

FlipTracer: Practical Parallel Decoding for Backscatter Communication
Meng Jin, Yuan He, Xin Meng, Yilun Zheng, Dingyi Fang, Xiaojiang Chen
MobiCom’17 (CCF-A) 2017
With parallel decoding for backscatter communication, tags are allowed to transmit concurrently and more efficiently. Existing parallel decoding mechanisms, however, assume that signals of the tags are highly stable, and hence may not perform optimally in the naturally dynamic backscatter systems. This paper introduces FlipTracer, a practical system that achieves highly reliable parallel decoding even in hostile channel conditions. FlipTracer is designed with a key insight: although the collided signal is time-varying and irregular, transitions between signals' combined states follow highly stable probabilities, which offers important clues for identifying the collided signals, and provides us with an opportunity to decode the collided signals without relying on stable signals. Motivated by this observation, we propose a graphical model, called one-flip-graph (OFG), to capture the transition pattern of collided signals, and design a reliable approach to construct the OFG in a manner robust to the diversity in backscatter systems. Then FlipTracer can resolve the collided signals by tracking the OFG. We have implemented FlipTracer and evaluated its performance with extensive experiments across a wide variety of scenarios. Our experimental results have shown that FlipTracer achieves a maximum aggregated throughput that approaches 2 Mbps, which is 6x higher than the state-of-the-art.
FitLoc: Fine-grained and Low-cost Device-free Localization for Multiple Targets over Various Areas
Liqiong Chang, Xiaojiang Chen, Yu Wang, Dingyi Fang, Ju Wang, Tianzhang Xing, Zhanyong Tang
IEEE/ACM Transactions on Networking (CCF-A) 2017
Many emerging applications driven the fast development of the device-free localization (DfL) technique, which does not require the target to carry any wireless devices. Most current DfL approaches have two main drawbacks in practical applications. First, as the pre-calibrated received signal strength (RSS) in each location (i.e., radio-map) of a specific area cannot be directly applied to the new areas, the manual calibration for different areas will lead to a high human effort cost. Second, a large number of RSS are needed to accurately localize the targets, thus causes a high communication cost and the areas variety will further exacerbate this problem. This paper proposes FitLoc, a fine-grained and low cost DfL approach that can localize multiple targets over various areas, especially in the outdoor environment and similar furnitured indoor environment. FitLoc unifies the radio-map over various areas through a rigorously designed transfer scheme, thus greatly reduces the human effort cost. Furthermore, benefiting from the compressive sensing theory, FitLoc collects a few RSS and performs a fine-grained localization, thus reduces the communication cost. Theoretical analyses validate the effectivity of the problem formulation and the bound of localization error is provided. Extensive experimental results illustrate the effectiveness and robustness of FitLoc.
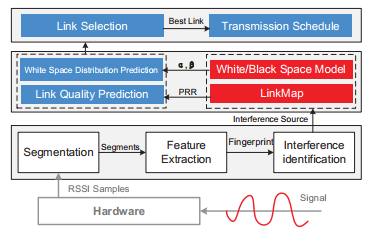
Smogy-Link: Fingerprinting Interference for Predictable Wireless Concurrency
Meng Jin, Yuan He, Xiaolong Zheng, Dingyi Fang, Dan Xu, Tianzhang Xing, Xiaojiang Chen
ICNP’16 (CCF-B) 2016
Operating in unlicensed ISM bands, ZigBee devices often yield poor throughput and packet reception ratio due to the interference from ever increasing wireless devices in 2.4 GHz band. Although there have been many efforts made for interference avoidance, they come at the cost of miscellaneous overhead, which oppositely hurts channel utilization. Our empirical results show that, a specific interference is likely to have different influence on different outbound links of a ZigBee sender, which indicates the chance of concurrent transmissions. Based on this insight, we propose Smoggy-Link, a practical protocol to exploit the potential concurrency for adaptive ZigBee transmissions under harsh interference. Smoggy-Link maintains an accurate link model to describe and trace the relationship between interference and link quality of the sender's outbound links. With such a link model, Smoggy-Link can obtain fine-grained spatiotemporal link information through a low-cost interference identification method. The link information is further utilized for adaptive link selection and intelligent transmission schedule. We implement and evaluate a prototype of our approach with TinyOS and TelosB motes. The evaluation results show that Smoggy-Link has consistent improvements in both throughput and packet reception ratio under interference from various interferer.
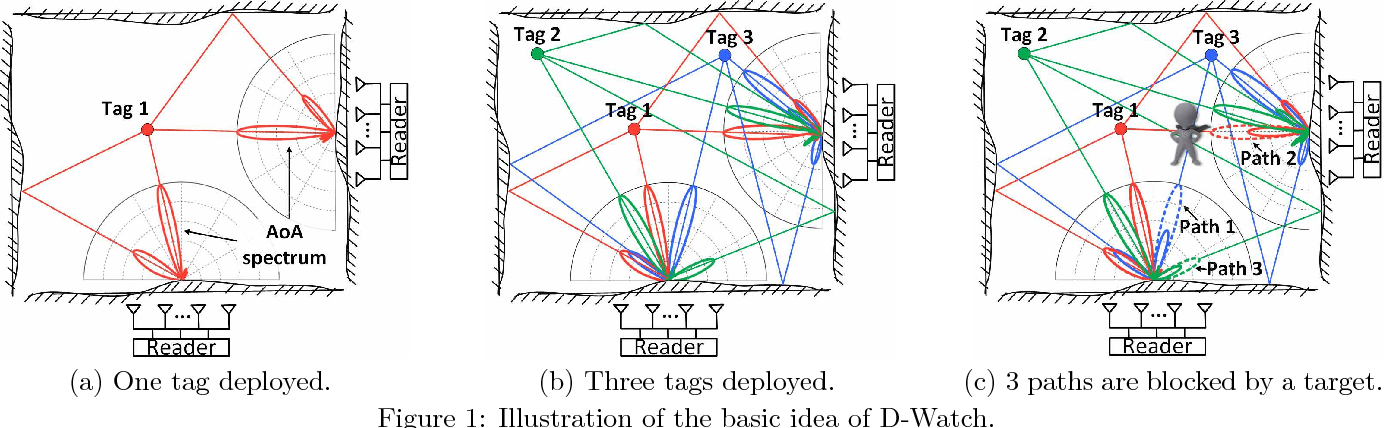
D-Watch: Embracing “bad” Multipaths for Device-Free Localization with COTS RFID Devices
Ju Wang, Jie Xiong, Hongbo Jiang, Xiaojiang Chen, Dingyi Fang
Co-Next’16 (CCF-B) 2016
Device-free localization, which does not require any device attached to the target is playing a critical role in many applications such as intrusion detection, elderly monitoring, etc. This paper introduces D-Watch, a device-free system built on top of low cost commodity-off-the-shelf (COTS) RFID hardware. Unlike previous works which consider multipaths detrimental, D-Watch leverages the "bad" multipaths to provide a decimeter level localization accuracy without offline training. D-Watch harnesses the angle-of-arrival (AoA) information from the RFID tags' backscatter signals. The key intuition is that whenever a target blocks a signal's propagation path, the signal power experiences a drop which can be accurately captured by the proposed novel P-MUSIC algorithm. The wireless phase calibration scheme proposed does not interrupt the ongoing communication. Real-world experiments demonstrate the effectiveness of D-Watch. In a rich-multipath library environment, D-Watch can localize a human target at a median accuracy of 16.5 cm. In a table area of 2 m×2 m, D-Watch can track a user's fist at a median accuracy of 5.8 cm. D-Watch is capable of localizing multiple targets which is well known to be challenging in passive localization.
SS Distribution-Based Passive Localization and Its Application in Sensor Networks
Liu chen, faingdingyi, yangzhe, jianghongbo, Xiaojiang Chen
IEEE Transactions on Wireless Communications (CCF-B) 2016
Passive localization is fundamental for many applications such as activity monitoring and real-time tracking. Existing received signal strength (RSS)-based passive localization approaches have been proposed in the literature, which depend on dense deployment of wireless communication nodes to achieve high accuracy. Thus, they are not cost-effective and scalable. This paper proposes the RSS distribution-based localization (RDL) technique, which can achieve high localization accuracy without dense deployment. In essence, RDL leverages the RSS and the diffraction theory to enable RSS-based passive localization in sensor networks. Specifically, we analyze the fine-grained RSS distribution properties at a variety of node distances and reveal that the structure of the triangle is efficient for low-cost passive localization. We further construct a unit localization model aiming at high accuracy localization. Experimental results show that RDL can improve the localization accuracy by up to 50%, compared to existing approaches when the error tolerance is less than 1.5 m. In addition, we apply RDL to facilitate the application of moving trajectory identification. Our moving trajectory identification includes two phases: an offline phase where the possible locations can be estimated by RDL and an online phase where we precisely identify the moving trajectory. We conducted extensive experiments to show its effectiveness for this application - the estimated trajectory is close to the ground truth.
LiFS: low human-effort, device-free localization with fine-grained subcarrier information
Ju Wang, Hongbo Jiang, Jie Xiong, Kyle Jamieson, Xiaojiang Chen, Dingyi Fang, Binbin Xie
Mobicom’16 (CCF-A) 2016
Device-free localization of people and objects indoors not equipped with radios is playing a critical role in many emerging applications. This paper presents an accurate model-based device-free localization system LiFS, implemented on cheap commercial off-the-shelf (COTS) Wi-Fi devices. Unlike previous COTS device-based work, LiFS is able to localize a target accurately without offline training. The basic idea is simple: channel state information (CSI) is sensitive to a target's location and by modelling the CSI measurements of multiple wireless links as a set of power fading based equations, the target location can be determined. However, due to rich multipath propagation indoors, the received signal strength (RSS) or even the fine-grained CSI can not be easily modelled. We observe that even in a rich multipath environment, not all subcarriers are affected equally by multipath reflections. Our pre-processing scheme tries to identify the subcarriers not affected by multipath. Thus, CSIs on the "clean" subcarriers can be utilized for accurate localization.
FitLoc: Fine-grained and Low-cost Device-free Localization for Multiple Targets over Various Areas.
Liqiong Chang, Xiaojiang Chen, Yu Wang, Dingyi Fang, Ju Wang, Tianzhang Xing, Zhanyong Tang
Infocom’16 2016
Device-free localization (DfL) techniques, which can localize targets without carrying any wireless devices, have attracting an increasing attentions. Most current DfL approaches, however, have two main drawbacks hindering their practical applications. First, one needs to collect large number of measurements to achieve a high localization accuracy, inevitably causing a high deployment cost, and the areas variety will further exacerbate this problem. Second, as the pre-obtained Received Signal Strength (RSS) from each location (i.e., radio-map) in a specific area cannot be directly applied to new areas for localization, the calibration process of different areas will lead to the high human effort cost. In this paper, we propose, FitLoc, a fine-grained and low cost DfL approach that can localize multiple targets in various areas. By taking advantage of the compressive sensing (CS) theory, FitLoc decreases the deployment cost by collecting only a few of RSS measurements and performs a fine-grained localization. Further, FitLoc employs a rigorously designed transfer scheme to unify the radio-map over various areas, thus greatly reduces the human effort cost. Theoretical analysis about the effectivity of the problem formulation is provided. Extensive experimental results illustrate the effectiveness of FitLoc.
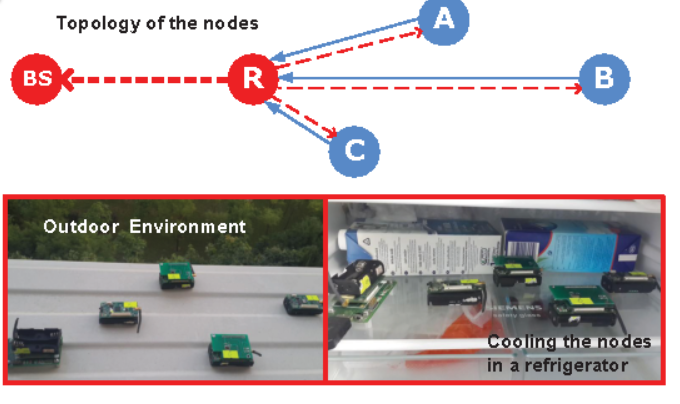
DualSync: Taming clock skew variation for synchronization in low-power wireless networks
Meng Jin, Tianzhang Xing, Xiaojiang Chen, Xin Meng, Dingyi Fang, Yuan He
Infocom’16 2016
The low-cost crystal oscillators embedded in wireless sensor nodes are prone to be affected by their working condition, leading to undesired variation of clock skew. To preserve synchronized clocks, nodes have to undergo frequent re-synchronization to cope with the time-varying clock skew, which in turn means excessive energy consumption. In this paper, we propose DualSync, a synchronization approach for low-power wireless networks under dynamic working condition. By utilizing time-stamp exchanges and local measurement of temperature and voltage, DualSync maintains an accurate clock model to closely trace the relationship between clock skew and the influencing factors. We further incorporate an error-driven mechanism to facilitate interplay between Inter-Sync and Self-Sync, so as to preserve high synchronization accuracy while minimizing communication cost. We evaluate the performance of DualSync across various scenarios and compare it with state-of-art approaches. The experimental results illustrate the superior performance of DualSync in terms of both accuracy and energy efficiency.